General Principles#
geoconnex.us is about publishing water data on the web in a manner similar to the way commercial entities publish information such that it is easily discoverable and useable by software developers to create feature-rich user experiences and useful information products.
Think about the way that a search for a movie title on a search engine instantly brings up a card showing that film’s director, cast, showtimes at nearby movie theaters or availability on various streaming platforms. Or how you can search in a maps application for gas stations or fast-food chains along your route. Or how a search for a city name and “population” might bring up an interactive line graph showing its population trend along with those of other cities. These sorts of things, as well as generally improved search results, are generally made possible due to the presence of “structured, linked data” within websites.
Structured data consists of specifically formatted, machine-readable descriptive information about the subject of the webpage, as well as in many cases, links to other webpages. For example, a webpage about a particular job posting on a job listing app might have structured information about the job title, work location, posting date, salary range, as well as link to the company homepage. Search engines then use “web crawlers”, which are special programs that go to webpages and harvest the structured data within them, to collect this structured data and aggregate it into a “knowledge graph”, a digital representation of all of the webpages and how they relate to each other. This graph is what allows for complex queries over decentralized data, like “find all the job postings that include the word data in the title within this salary range and work locations in these two metro areas”.
Knowledge graphs can only be as good as the quality and interpretability of the structured data that is harvested into them. To improve the set of structured data on the web available to work with, Google, Bing, and Yahoo have partenered together to create general framework for webpages to have structured linked data at schema.org. This is a specific vocabulary of terms that allows unambiguous representation of the attributes of subjects of websites. For example, https://schema.org/name is the standard identifier for the name of something, and https://schema.org/longitude is the standard identifier for the longitude of a location. JSON-LD is a special format that structured data can use, leveraging schema.org and other vocabularies, to be easily read by web crawlers.
Data publishers: Structured water data on the web#
geoconnex.us augments the above framework with a strategy and guidance for data publishers to anchor webpages to hydrologic features of interest and structured data to vocabularies specifically designed for water science to create a knowledge graph for water data. The fundamental architecture of geoconnex.us has four components:
Real-World Features that have…
Persistent Identifiers (formatted as URLs) that point to…
Landing Content (web pages) that include…
Structured, Linked Data formatted as JSON-LD that include references to other Persistent Identifiers
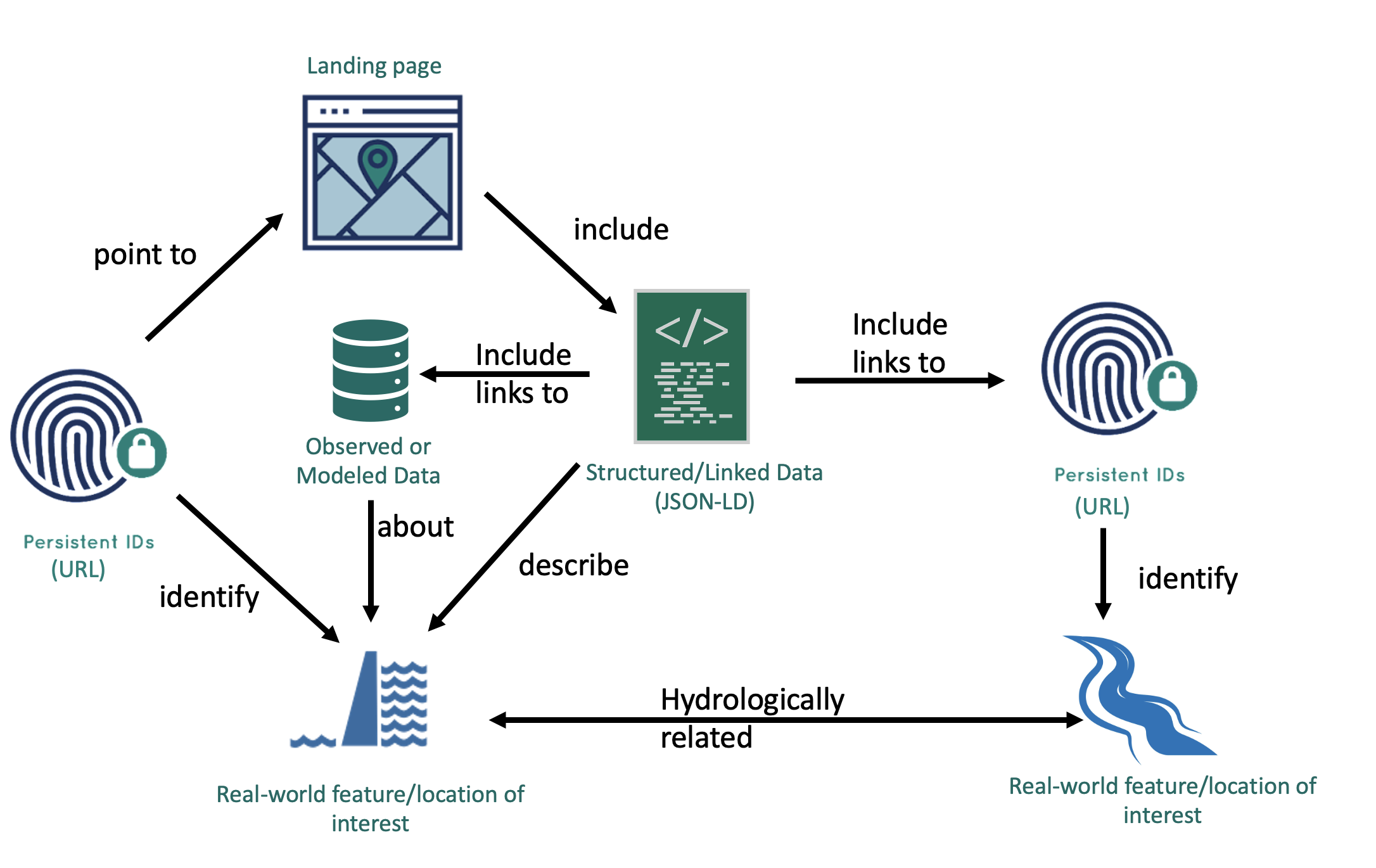
Fig. 1 The geoconnex.us data publication fundamentals.#
geoconnex.us: Organizing the structured data#
The geoconnex.us system includes some important infrastructure that helps organize the structured data that data publishers put on the web and make it useable to data users. These elements include:
Persistent Identifier Registry to help data publishers mint persistent identifiers and populate a…
Sitemap of all identifiers to allow a…
Harvester to collect structured data so that it can be assembled into a
Knowledge Graph that data users can interact with through…
APIs and Search Interfaces
Of course, this website also includes comprehensive Documentation that provides detailed guidance, templates, and examples on how to contribute to and use the knowledge graph.
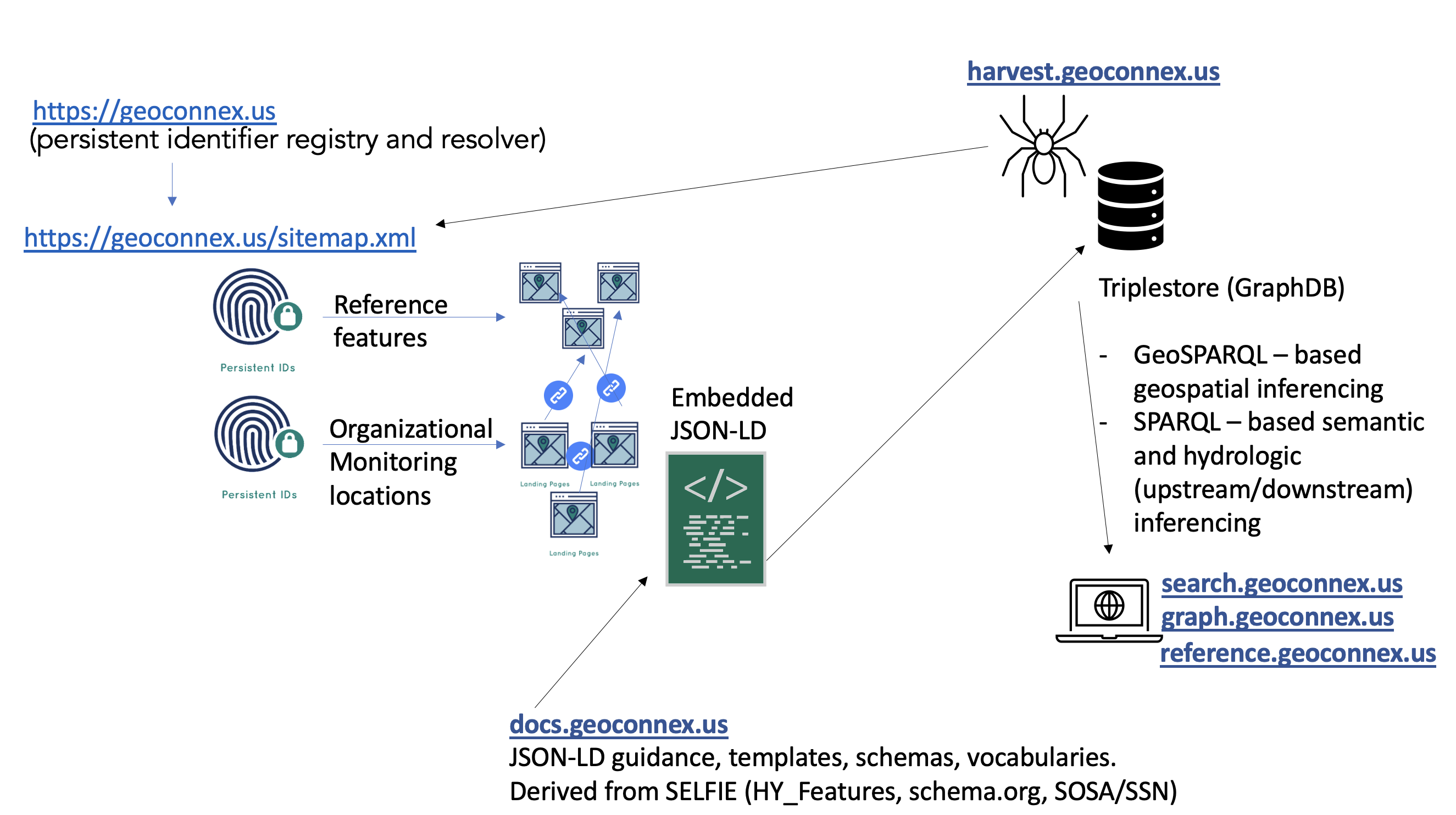
Fig. 2 The geoconnex.us architecture#
The remaining parts of this section give more detailed documentation for each of the elements outlined.