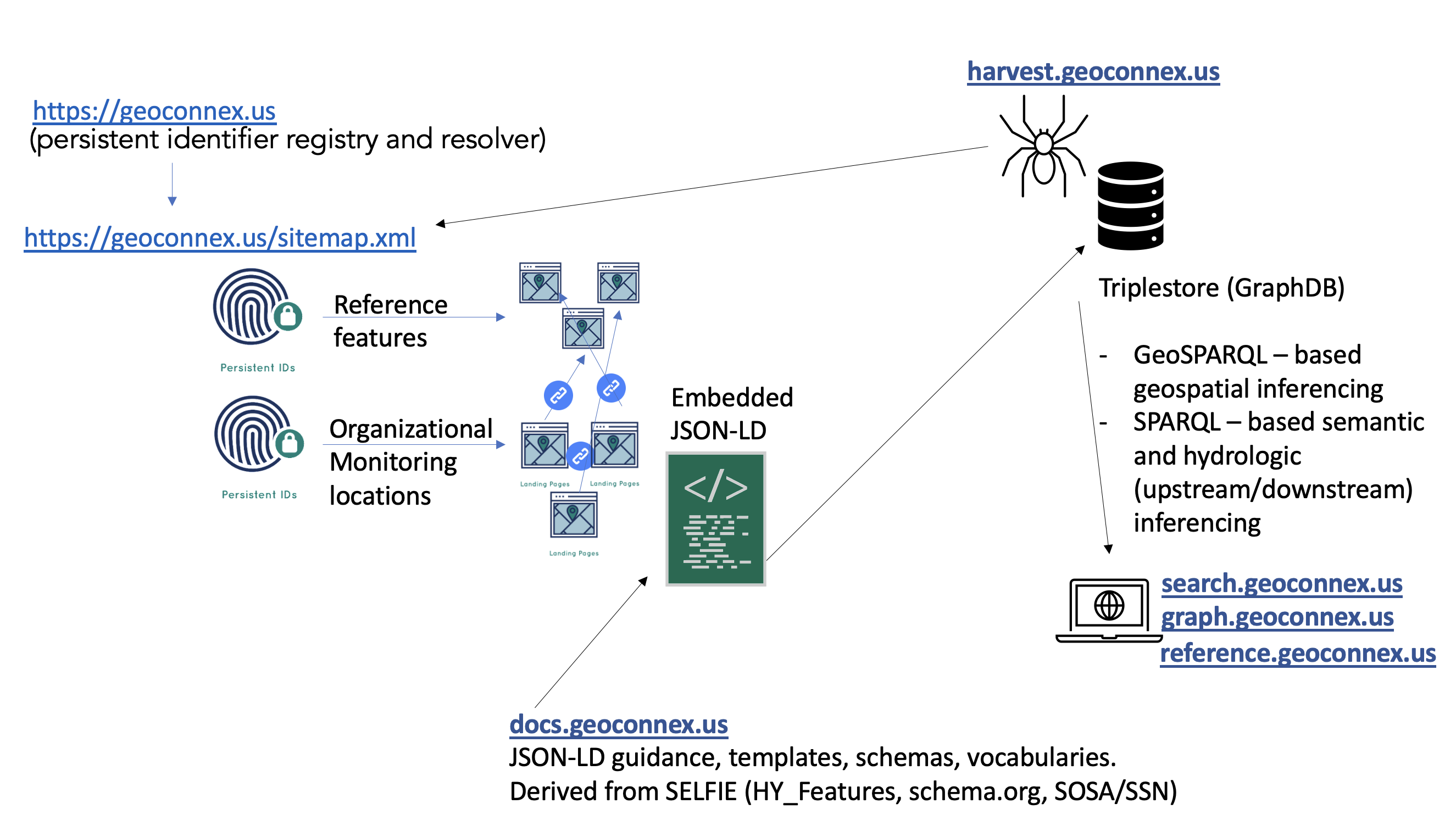
Overview of Geoconnex Architecture
System Components within geoconnex.us
The Geoconnex.us system includes multiple infrastructural components that are each necessary to achieve a robust, queryable, and stable knowledge graph for water data.
- The Persistent Identifier Registry helps data publishers mint persistent identifiers and create a system that is stable, even if the underlying resources change
- The Sitemap of all identifiers to allows a crawler to easily traverse all websites in the network
- The Harvester collects structured data so that it can be exported as knowledge graph triplets
- The Knowledge Graph allows data users to interact with linked data through a search interfaces
Populating the Graph
The Geoconnex knowledge graph is populated by the following process:
- An organization creates an endpoint for their water data and associates a list of persistent identifiers with their endpoints
- The organization submits a pull request or submits the form at register.geoconnex.us to upload their data
- The Geoconnex harvester finds the endpoints via their published PIDs and downloads the JSON-LD for each endpoint
- Using the JSON-LD data, the Geoconnex crawler produces semantic triples in the PROV Ontology
- The Geoconnex crawler populates the Geoconnex graph database
A Visual Representation of the Geoconnex Architecture